Attention-Related Image Captioning (4)
一、Exploring and Distilling Cross-Modal Information for Image Captioning, IJCAI2019
作者认为深层次的图片理解需要与图片区域相关的视觉注意力和与对应属性相关的语义注意力,所以作者从跨模态(包括视觉和文本属性)的视角提出了Global-and-Local Information Exploring-and-Distilling (GLIED) 方法,如下图所示,左边是基础模型,右边是利用全局和局部的源信息的完整模型。
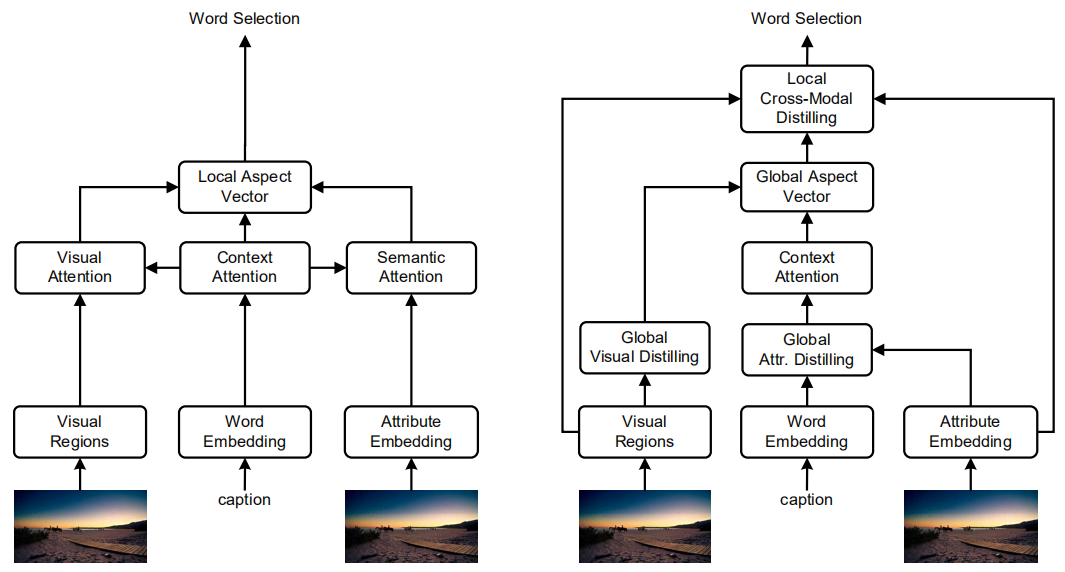
视觉特征善于说明形状和颜色,而文本属性善于用高层次的语义概念表达图片,比如物体、属性和关系。对于视觉区域,作者使用Button-Up中的基于faster rcnn的特征,对于文本属性,采用多实例学习来构建了一个属性提取器,并通过嵌入矩阵将属性词投影成向量表示。
1、基础模型
如上图的左图所示,基础模型是基于Transformer的思想,它的基础模块采用多头注意力模型,其中视觉和语义注意力模块分别对视觉特征和属性特征进行注意力操作,上下文注意力模块通过上一个时间步的输出以及之前已经生成的所有单词进行注意力操作生成上下文信息,并用于指导视觉和语义注意力模块。最后将三个注意力模块的输出进行融合得到局部向量,并投影到单词空间经过采样得到当前生成的单词。可以通过交叉熵损失和强化学习的方式训练。
2、GLIED模型
1)Global Visual Distilling
当我们试图描述一张图片时,常常会关注于某一个物体和它周围的区域,并且会寻找常常和该物体一起出现的物体,而这些在空间或语义上相关的集合构成了我们所关注的一个固有的组,所以Visual Distilling就是去学习这种区域分组。作者采用self-attention实现这种效果。该模块得到的表示是全局的,因为它不与特定的描述上下文耦合,而是学习图像区域的一般组合。
2)Global Attribute Distilling
在语言领域,我们也有能力在构成句子时进行联想和使用搭配。同样采用self-attention机制,但是与基于形状或纹理的图像区域不同,简单地组合属性可能会导致不实际出现在图像中的通用搭配,而这个对描述生成有误导作用。因此为了学习有意义的搭配,作者使用一个枢轴词并收集这个词的搭配,以便在每个解码时间步,使用不同的属性组合。
3)Global Aspect Generation
上下文注意力模块对输入的单词嵌入进行self-attention操作,之后再通过一个多头注意力模块得到全局向量。
4)Local Cross-Modal Distilling
和基础模型类似,使用全局向量分别指导视觉和文本两个模态的特征生成,同样采用多头注意力模型,最后融合得到局部向量。
二、X-Linear Attention Networks for Image Captioning, CVPR2020
1、解决问题
如下图(a)所示,在传统的注意力机制中,通过对key(编码后的图片特征集合)和query(解码器的隐藏状态)的线性融合计算注意力权重,之后用于对value(编码后的图片特征集合)进行加权求和得到当前的注意力特征,最后用于生成描述,公式表示如下:
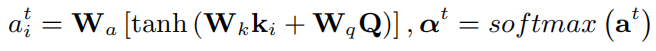
作者认为虽然这种方式实现了视觉和自然语言的交互,但只涉及到一阶的特征交互,这严重限制了图片描述生成过程中复杂的多模态推理的能力。
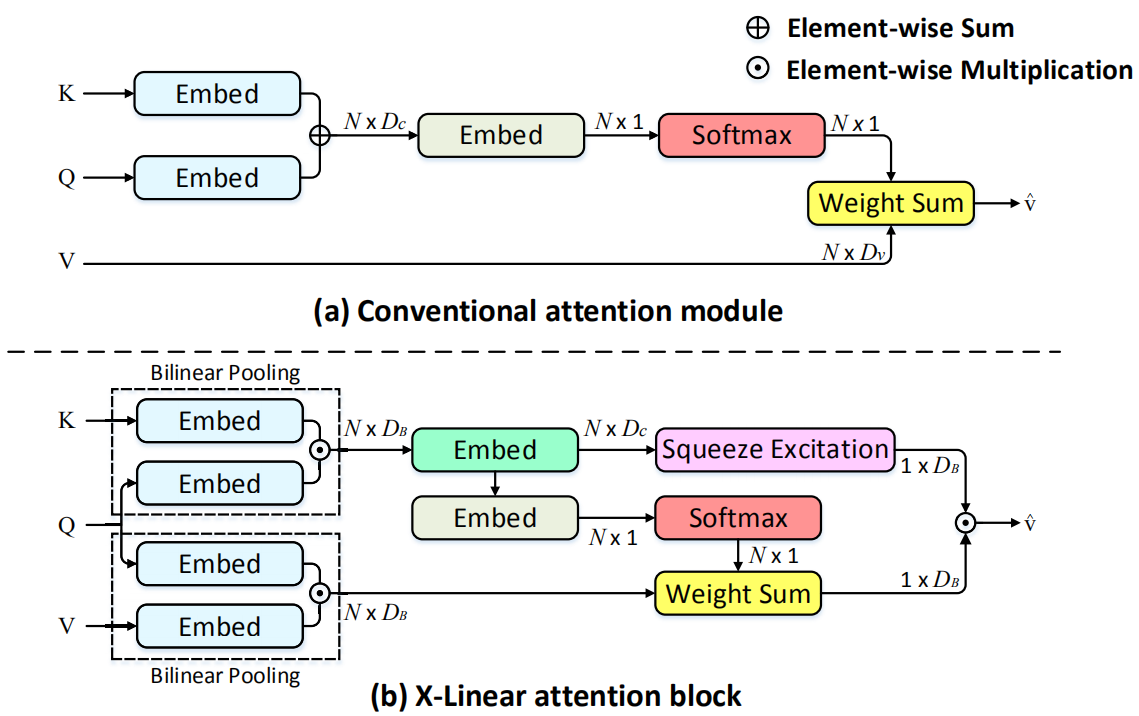
2、解决方法
如上图(b)所示,作者设计了X线性注意力块(X-Linear attention block),从二阶交互开始相关的探索,并且之后扩展到无穷阶的特征交互。之后,作者提出X线性注意力网络(X-LAN),将X线性注意力块整合到编解码框架中来利用模态内和模态间的高阶交互信息,促进单模态的特征表示以及多模态的推理能力。
1)X线性注意力块
首先通过双线性变换得到K和Q、V和Q之间的联合特征表示:
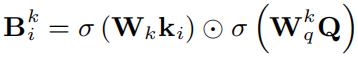
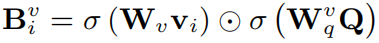
之后通过空间和通道两个角度来探索特征之间的交互。对于空间信息,和传统方法类似,首先计算注意力权重,之后加权求和,其中计算注意力权重公式如下:
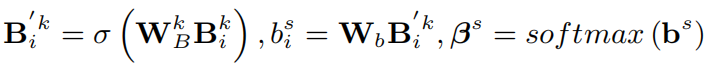
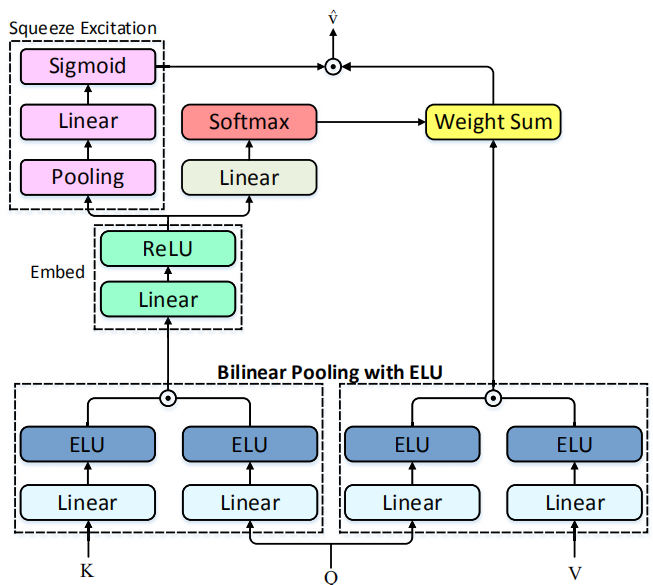
对于通道信息,执行squeeze-excitation操作,其中squeeze操作是通过平均池化来增强特征表示,得到一个全局的通道描述:
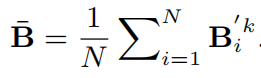
之后,通过excitation操作得到通道注意力分布:
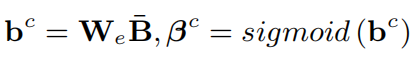
最后,通过融合空间和通道特征得到注意力特征:
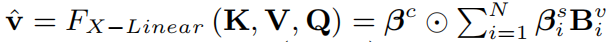
高阶交互:通过叠加X线性注意力块可以实现特征的高阶交互,此时,将上一块输出的注意力特征作为当前块的query,并通过该注意力特征对key和value进行更新:
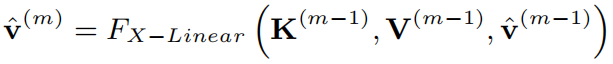
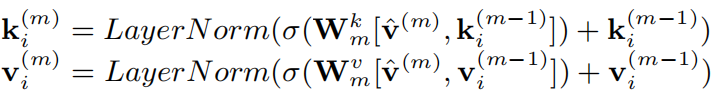
无穷大阶交互:一个自然的想法是通过叠加更多的X线性注意力块实现无穷大交互,但是这样会占用巨大的内存和计算资源,因此,如下图所示,作者加入指数线性单元(ELU)对Q、K、V进行指数操作来模拟无穷大阶特征交互。下式证明指数变换后双线性向量中的每个元素都反映了无穷大阶相互作用:
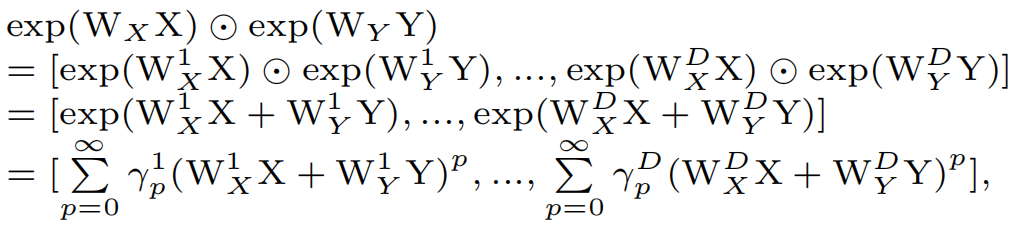
2)X-LAN模型

如上图所示,将多个X线性注意力块加入到编码器中,通过高阶的模态间特征交互增强了图片级别和区域级别的特征表示。首先对提取出的图片区域特征集合进行均值池化操作得到第一个query,然后将特征集合作为第一个key和value,通过X线性注意力块和特征更新模块得到新的注意力特征和区域特征集合,之后迭代M次,最后所有的X线性注意力块输出的注意力特征作为图片级别特征集合,并且最后更新模块得到的特征作为增强的区域级别特征。在解码器中,同样使用X线性注意力块增强视觉和语言两个模块之间的交互。